邂逅Node
1:浏览器内核
Geoko,Trident,Webkit,Blink
但是前端经常提到的浏览器内核一般是浏览器的排版引擎
排版引擎 ,浏览器引擎,页面渲染引擎,样排引擎
2:比较常见的javascript引擎
SpiderMonkey:js作者开发
Chakra:微软开发
JavascriptCore:Webkit中的js引擎 apple开发
V8:谷歌的,脱颖而出
V8执行js代码的原理
3:Node
node是基于v8引擎的js运行环境
如果想在一台电脑运行多个node版本 那么可以借助nvm与n工具
但是这两个工具不支持windows,不过有其他人开发出了支持windows的版本
4:全局对象和模块化开发
process
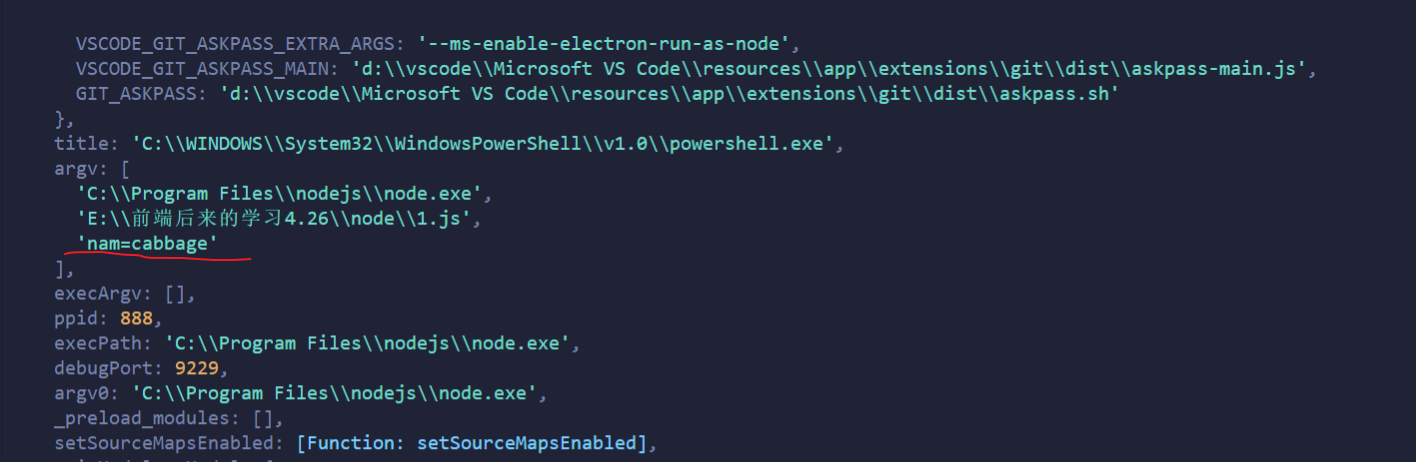
node index.js env=development
可以在后面跟随传递参数 在index.js中根据console.log(process.argv)获取
console.clear() 清空
console.trace() 追踪 打印函数调用栈
常见全局对象
require,__dirname,__filename,module,URL,exports等,可以去官网查看更多全局对象
process,global,
计时器全局对象:setTimeout,setInterval,setImmediate(立即执行)
process.nextTick(()=>{
console.log(‘process.nextTick’)
})
1 | setTimeout(()=>{ |
有的对象是因为在每个模块中都有,看起来像全局变量,在命令行是无法使用的
global全局对象:
1 | console.log(global) |
global与window相似
window会将var的变量自动挂载到window,global不会,所有global.变量是不对的
模块化
最终目的:将程序划分为一个个结构,每个结构包含自己的逻辑到=代码,不会影响到其他作用域
可以暴露出变量,函数,对象供其他结构导入使用
js缺陷:var定义的变量作用域问题,没有模块化的问题 可以用立即执行函数解决
1 | var module = (function(){ |
Commonjs
exports,module.exports导出 require导入
1 | a.js |
module的原理 每个模块默认有个module指向一个空对象 exports.name = name 是将空对象中的name 变为 name
require是想办法将这个对象作为返回值返回 实际上是浅层拷贝
module.exports 与 exports 区别 exports是Module的一个实例 实际上exports是使用的module.exports
源码中将 module.exports = exports
require细节
require的查找规则
1:path/http模块
2:./ ../ / 开头 有后缀名按照后缀名查找 否则先查找不带后缀名 => .js => .json => .node
如果是目录名 那么就会去该目录查找.js .json .node
3:既不是模块也不是目录 那么就会去node_modules查找 //not found
模块的引入查找是数据结构图的便遍历 广度优先和深度优先
Node是采用的深度优先
AMD
require.js cuel.js
CMD
sea.js
ES Module
使用import 与 export
默认导出exort default 一个模块只能有一个
es module加载过程
是异步的script type=”module” 相当于加了async 并不会影响加载
es modole 原理
1 | export { |

