vue3做了什么样的优化?为什么需要这些优化?
vue从1-2最大的变化就是引入了虚拟dom
vue3的优化
更好的代码管理方式monorepo,将不同模块拆分到不同的package中
每个package有各自的API,类型定义和测试
package-比如reactive,是可以独立于vue.js使用的,这样用户如果只想使用单个vue的能力而不必去依赖整个库。减少了引用包的体积大小,v2是做不到的
import { reactive } from ‘vue’
采用了ts开发
v2是flow,v3使用ts重构
flow是facebook出品的js静态类型检查工具,以非常小的成本对已有js代码迁入,v2采用时就是考虑到了flow的轻便灵活性
但是flow对于复杂场景类型十分不友好,v2源码有吐槽

ts则相反,更好的类型检查
性能优化
减少了包的体积,移除冷门的feature,使用了tree-shaking
tree-shaking是依赖es6的静态结构,import和export。通过编译阶段的静态分析,找到没有引入的模块并打标记
间接减少了vue包的体积
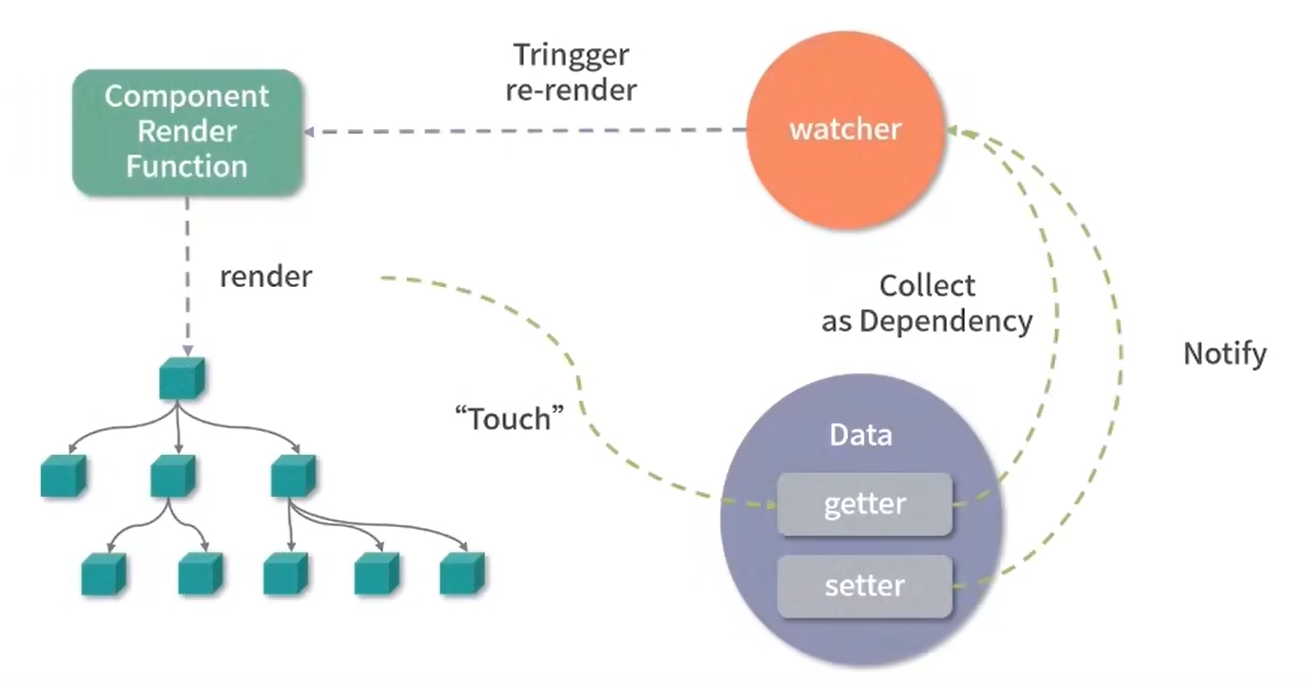
数据劫持优化
vue的数据从1x版本开始就是响应式的
1 | vue2是通过object.deineProperty(data,'a',{ |
编译优化
除了在数据劫持部分的优化,也可以在耗时较多的patch阶段想办法
2x
3x
通过在编译阶段优化编译结果,实现运行时patch过程的优化
2x版本对于数据更新并触发重新渲染的粒度是组件级的
每次diff都会全部对比,vnode和模板大小正相关
当只有小部分更改时,多余的便利是对性能的浪费
v3通过编译阶段对静态模板的分析,编译生成了Block tree //将模板基于动态节点指令切割的嵌套区域,每个区块内部的节点结构是固定的,每个区块只需要一个Array来追踪自身包含的动态节点
借助block tree vue将vnode更新性能由整体模板大小相关变成了与动态内容修改的数量有关
3x版本在编译节点还包含对slot的编译优化,事件侦听函数的缓存优化,并且在运行时重写了diff算法
优化逻辑组织
3x还提供了comonsition api
2x被称为options api
options api在组件小的时候一目了然,大的时候就很复杂,每当修改某一个关注点,就需要上下滑动变动多个位置
优化逻辑复用
v2采用mixins,可以定义props,data,容易导致定义相同名称变量,导致命名冲突
而且在使用时,对于不在当前组件定义的变量等事物,使用时数据来源不清器
v3采用hook方式
更好的类型支持
因为componsition具备更好的类型支持,因为都是函数,类型容易被推导,和v2不同,v2使用this不容易推导。
componsition api对tree-shaking更友好,代码压缩更容易
引入RFC:使每个版本改动可控
v2部分采用REF(reqquest for comments) //为新功能进入框架提供一个一致且受控的路径
v3大规模采用RFC,你可以了解每一个feature采用或者被废弃的前因后果
小缺点:
vue3是采用es6的语法开发,有些api如proxy是没有polyfill的,这就意味着官方需要单独出一个ie11的compat版本来支持ie11
v2官方声明继续维护18个月,也就是说18个月以后,如果你的项目出了什么问题,那么就需要你自己阅读源码解决

